
Are we doing vulnerability management all wrong? Part 1: Probably
Are we doing vulnerability management all wrong? Part 1: Probably
A call to action for more innovation and focus on proactive vulnerability management


Update: part 2 is out!
Is it just me or is vulnerability management having a renaissance moment? CVSS 4.0 is hot off the presses, EPSS 3.0 was released earlier this year, and SSVC is finally getting the attention it deserves as a meaningful alternative to CVSS.
And yet, even with all of this innovation happening around vulnerability prioritization methods, truly efficient and effective vulnerability management still seems out of reach for many.
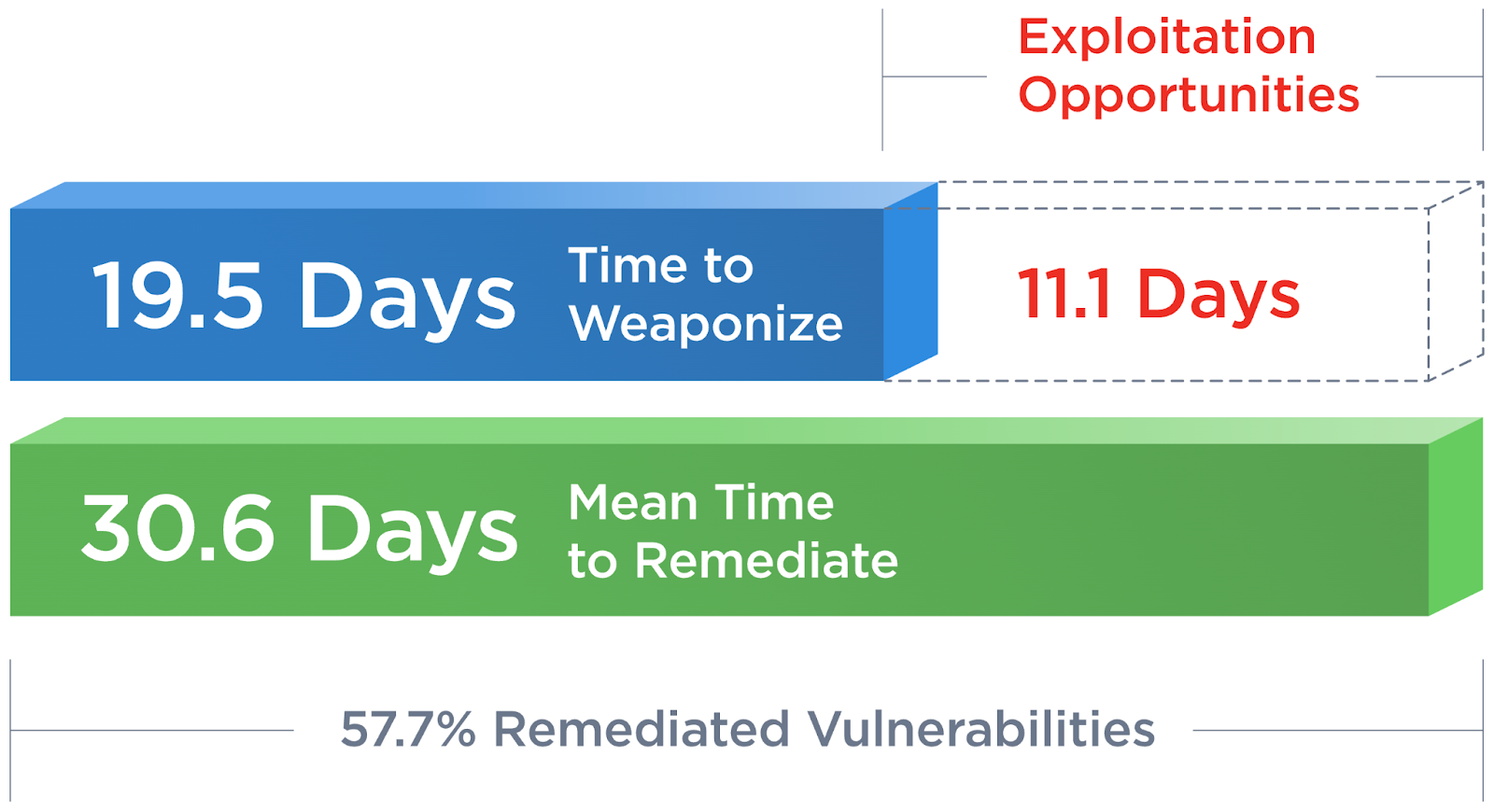
Why is that?
Is vulnerability management a fundamentally intractable problem with an upper limit on the proportion of vulnerabilities any organization can fix?
Is it destined to be a game of cat and mouse that attackers tend to win in the long run?
Or, perhaps, are we approaching vulnerability management all wrong?
Background
I’ve spent the past 11+ years focusing on vulnerability management from various perspectives: security operations, application security, cloud security, network security, and GRC. In that time, through direct experience, learning from others, reviewing research, and experimenting with industry best practices, I’ve come to the conclusion that we’re approaching vulnerability management all wrong.
Ok, I’m being slightly hyperbolic. But in all honesty, we as an industry seem excessively focused on reactive vulnerability management strategies that amount to peering into a high-tech crystal ball to predict what vulnerabilities on which of our assets are most likely to be exploited and result in the worst impact, and then focusing our remediation efforts solely on those vulnerabilities.
This bias toward reactive vulnerability management is as much understandable as it is untenable: remediating vulnerabilities is a painstaking process, and no organization’s mission is “keep our sh!t patched and vulnerability free” - indeed, far from it. However, I contend that we have overcorrected our focus on reactive strategies at the expense of proactive ones, resulting in remarkably bad vulnerability management outcomes over the years.
So, let’s talk about what proactive vulnerability management is and what else we can do to innovate it. In this article, I’m going to describe:
The key differences between reactive and proactive vulnerability management
An example framework and strategy for proactive vulnerability management
I plan to release future articles that cover additional topics, such as how to better balance and integrate reactive and proactive vulnerability management strategies, examples of specific techniques and tools to use to put these ideas into practice, etc.
Until then, let’s dive in!
Reactive vs. Proactive Vulnerability Management
Reactive vulnerability management is the approach that the growing array of four letter acronyms and proprietary vulnerability risk scoring methods are propping up. For many security practitioners, it is the all-too-familiar Sisyphean hamster wheel of scan -> triage -> report → patch that never seems to truly move the needle over the long run.
{kind=link}
{kind=link}
It posits that because we’ve tried and failed over the years to “patch all the things”, we must settle on only patching what we think attackers are most likely to exploit on systems that we as defenders believe will be impacted the worst. This reactive approach is commonly referred to as “risk-based vulnerability management.”

Proactive vulnerability management, on the other hand, is any activity that remediates vulnerabilities without waiting to scan, triage, or report on them. It posits that, over time, you can patch just about every piece of software that can be patched.
At its core, this concept isn’t all that groundbreaking: it ultimately boils down to solid patch management, configuration management, and system hardening. InfoSec practitioners have long talked about the fundamental importance of each of these, within and outside the context of vulnerability management. These aren’t new ideas by a long shot.
Unfortunately, I don’t see us as an industry investing nearly enough time and energy into innovating in areas of proactive vulnerability management. This lack of innovation is holding us back from being able to consistently fix vulnerabilities faster than attackers exploit them.
New Ideas for Proactive Vulnerability Management
While patch management, and especially automated patching, is often mentioned in discussions about how to do vulnerability management really well, I have rarely come across any discussions about how to do patch management really well. Sure, there are well-known vendor tools in this space, such as SCCM, BigFix, and Automox. However, these are just patch automation and deployment tools that don’t have much of an opinion about how you ought to do patch management. More often than not, they simply reinforce reactive vulnerability management by focusing your patching efforts around known CVEs, CVSS scores, etc.
So, what would it look like to innovate in this area to modernize patch management with a much more proactive focus?
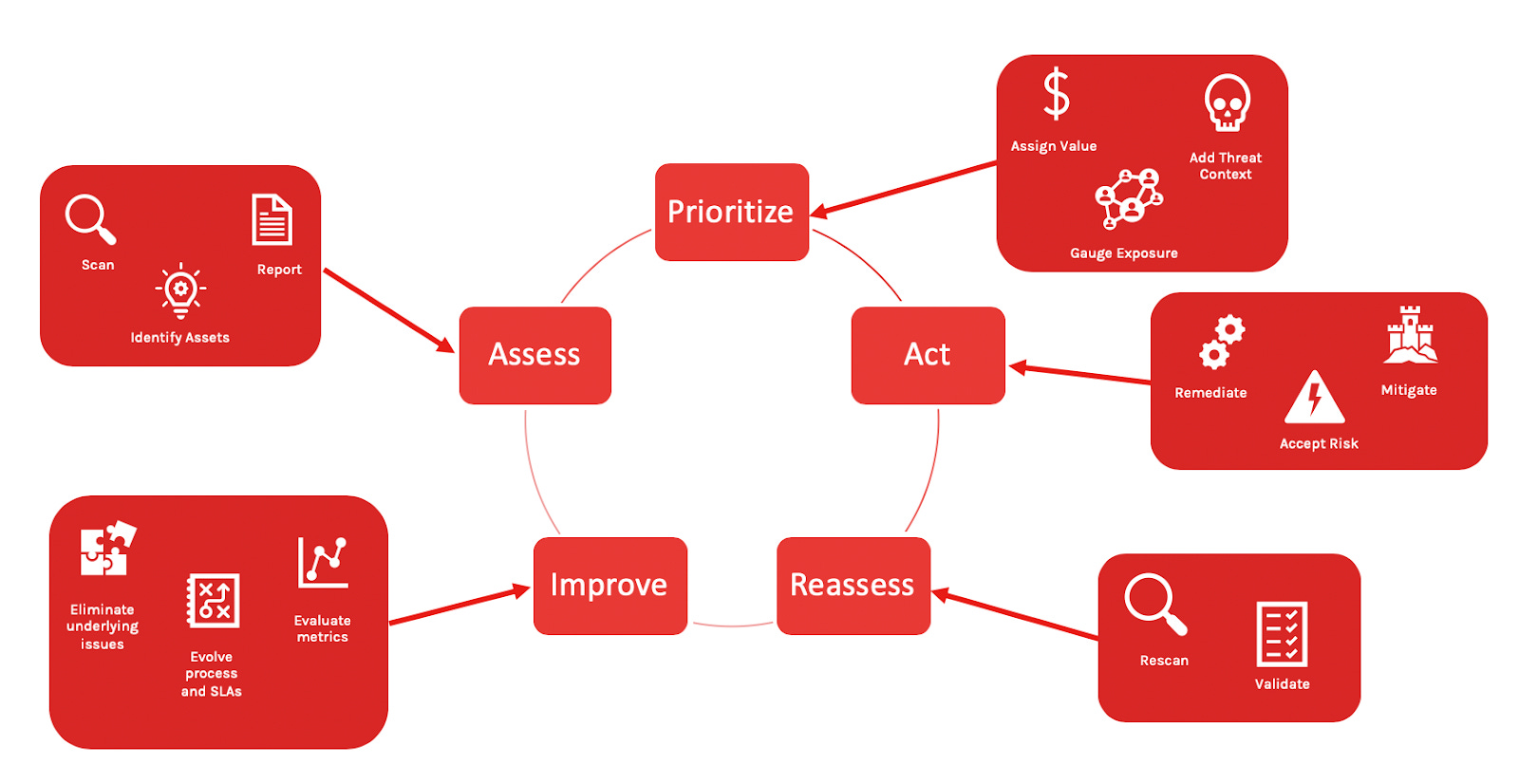
Proactive Vulnerability Patch Management Lifecycle (PVPM)
This wouldn’t be a thought leadership article about vulnerability management without another four letter acronym! Joking aside, what I refer to here as “PVPM” is how I envision proactive vulnerability management at a high level.

It’s a continuous lifecycle that is intended to produce high quality and highly effective auto-patching workflows that fix vulnerabilities fast without waiting to scan for them.
It’s a framework meant to enable organizations to consistently beat attackers at the vulnerability management game by driving a threat-centric focus around what to start auto-patching, when, how, and how often.
Automation is a must for this to work and is intended to be a key aspect of each stage in every phase of this lifecycle.
Let's break down what each phase and their corresponding stages entails.
Inventory
Like any good security practitioner knows, you can’t secure what you can’t see. Whether we’re talking about desktop software, server software, application libraries, container images, or anything in between, having a complete and continuously updated software inventory is absolutely essential to understand what needs patching.
Usage Analysis: this step of the inventory phase is all about understanding how software is used on systems. Is a particular piece of software running constantly, day in and day out? Or does it only run when a user launches it as needed? Or, perhaps, has it never run and thus is worth removing from a system entirely, permanently and proactively shrinking its vulnerability attack surface?
Prioritize
For all the software you’ve inventoried, the prioritize phase is all about figuring out which software is inherently most at risk of having vulnerabilities in it that get exploited by attackers.
In other words: whether you already have some software being regularly patched or you're starting entirely from scratch, you should focus your efforts on incrementally building new auto-patching workflows for software based on the following vulnerability attributes.
Attack History: has this software ever appeared on CISA’s KEV or other “actively targeted” vulnerability intel lists? Attack history is a strong signal that a piece of software has been, and likely will continue to be, an attractive target for attackers when conducting real-world attacks.
Exploit History: has this software ever had exploit code or methods published for vulnerabilities associated with it? The existence of publicly known exploit methods doesn't always mean attackers have bothered targeting their vulnerability exploitation efforts at a piece of software; however, it does serve as a good signal of software that is more likely to end up in attackers’ cross-hairs in the future since vulnerabilities with known exploit methods are easier to target than those without them.
Vulnerability History: has this software ever had vulnerabilities published as CVEs, GHSAs, etc? Compared to the other two attributes listed above, this is the weakest prioritization signal to use. However, software with a much longer history of published vulnerabilities seem to have a generally higher likelihood of being targeted by attackers compared to software with less or no vulnerability history (at least, according to my interpretation of the research behind EPSS).
Exposure Analysis: does this software process user-controllable data, and if so, from where? For example: a vulnerability that exists in a software component that processes user-controllable data that is ultimately received from the internet is most exposed (and thus most easily exploited) compared to one that processes machine-produced data from a local file system.
Patch
This is where all of the fun happens. This phase is intended all about frequently checking for new security updates and applying them as soon as they’re available.
Create Tests: in my experience, patch testing is one of the least rigorous and most underdeveloped aspects of patch management. Raise your hand if your organization’s approach to patch testing for things like end user devices is “roll out patches to 5% of users and wait to see if anyone files any tickets about BSODs / kernel panics.” Compared to modern approaches to software testing (unit testing, regression testing, test coverage metrics, etc.), testing in the context of patch management is generally immature - but it doesn’t have to be! We can apply these same modern software testing paradigms to patch management to ensure we are rigorously, and automatically, vetting the success of a newly installed patch before deploying it to the masses.
Run Tests: once you’ve created your (automated) tests for your the software you’re creating an auto-patch workflow for, it’s time to…well, test your tests! Make sure they’re successfully detecting evidence of bad patches.
Deploy Auto-Patch: once your patch tests pass, it’s time to #shipit. If you’re patching a large fleet of similar assets (e.g. end user computers, production compute servers/containers), use deployment rings and canaries to incorporate quality control mechanisms and feedback loops for detecting bad patches that your tests may have missed. When patching-related issues are detected or suspected, halt and, if possible, rollback patches.
I suspect that the “Inventory” phase and “Patch” phase are pretty straightforward for most folks, but the “Prioritize” phase might be more obscure. To better clarify what the “Prioritize” phase entails, I’d like to introduce a patching prioritization decision making model called…
Stakeholder-Specific Patching Prioritization (SSPP)
Sorry, I had to! There’s been enough innovation in the realm of four-letter acronyms for vulnerability management concepts that I’m going to shamelessly copy SSVC for naming this next framework as SSPP. For all of my software development friends out there who seize every opportunity to optimize and compress information, you may simply refer to this as s2p (just kidding, please don’t).

The crux of this framework is to drive focus around which software to build auto-patching workflows for and in what order. The intent is that once you've created a reliable auto-patching process for a piece of software, it will ensure that the latest security updates for a piece of software are proactively installed soon after they're made available.
Unlike SSVC, the decision points in this model are intended to be as simple as possible (but no simpler) to facilitate efficient yet still effective prioritization of creating auto-patching workflows. There is still room for additional prioritization criteria to help deal with “tie breaker” scenarios (e.g. “I’ve got 100 pieces of software that fall into the P1 category - which of those should I focus on first?”).
Here’s an example prioritization matrix based on these attributes. If you’re starting from scratch and you don’t have any auto-patching workflows created, this model is intended to guide your focus in choosing which software to create auto-patching workflows for before others.
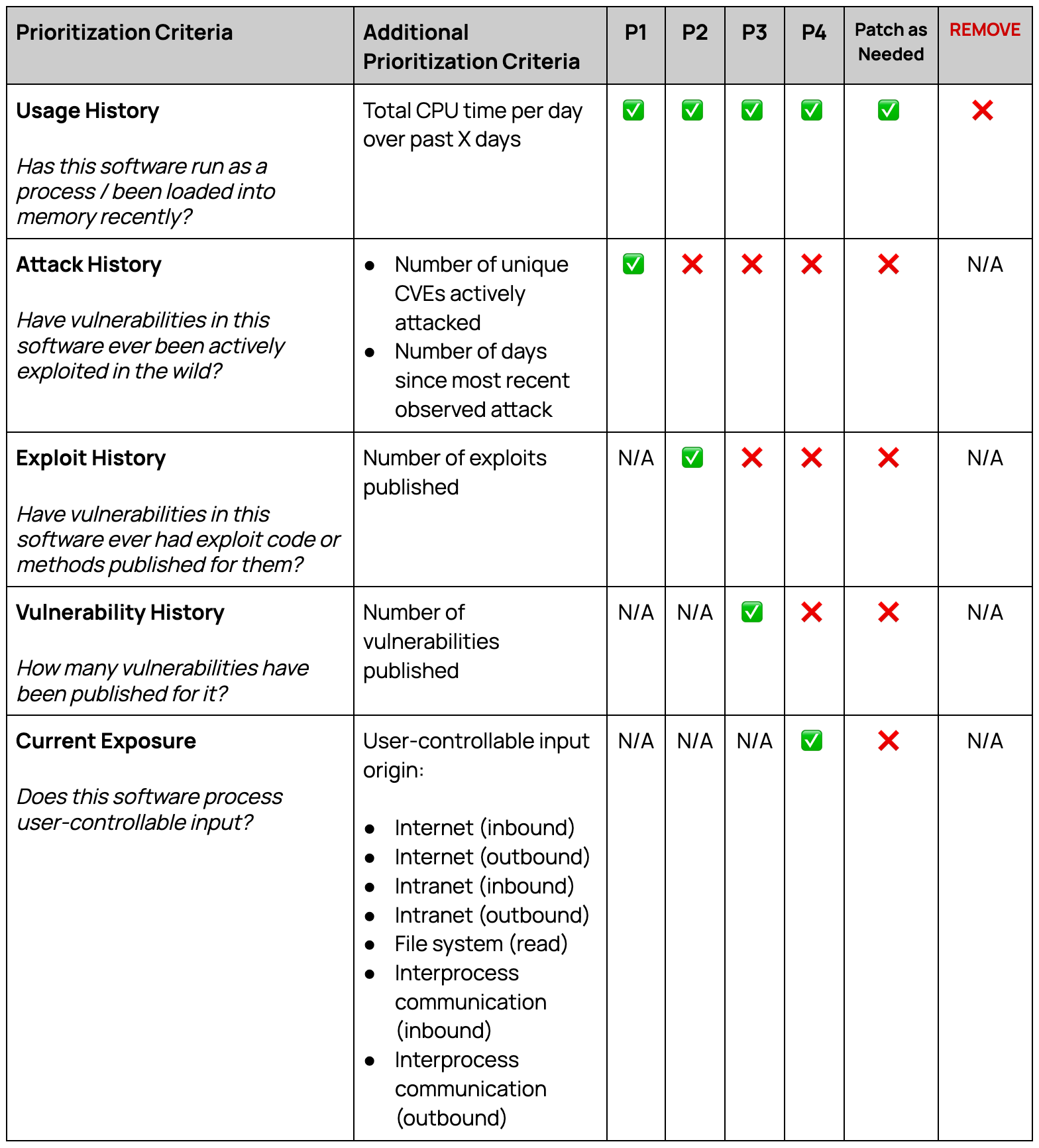
Attack History Analysis Example
Let’s step through an example to see how finer-grained prioritization criteria at the “Attack History Analysis” stage helps with providing a risk-based approach for building auto-patching workflows. Again, the idea behind PVPM and SSPP is that all of this analysis and decision making needs to be automated for it to scale efficiently and effectively.
Let’s assume for a moment that
Our organization has every software product actively in use that is mentioned in CISA’s KEV list (see this snapshot of data I set aside for this example).
We don’t have auto-patching in place for any of them
When examining this data in the aggregate, we can quickly see which software product to focus our auto-patching efforts on first, second, third, etc.

Thankfully, software products like Windows, iOS, macOS, and Chrome have reliable built-in auto-patching mechanisms that we can enable to implement some basic auto-patching in our environment. Also, security patches for these products tend to be very stable, so we can safely skip implementing rigorous patch testing for them (for now).
But what about Cisco IOS, Oracle WebLogic, and Apache Struts? Auto-patching these components is unfamiliar, and even scary, territory for us. However, that fear shouldn’t stop us from defining and implementing a rigorous and automated patch testing and deployment process for them. Now that we’ve implemented basic built-in auto-patching for the other higher risk software in my environment, we’ve bought ourselves more time to focus on creating and rolling out rigorous auto-patching for these trickier-to-patch systems.
Proactively building out auto-patching workflows for these trickier-to-patch systems puts us in a much stronger position to engage in emergency patching in the event a new actively exploited vulnerability is discovered in the wild for them. Rather than engaging in a panicked, rushed, and error-prone reactive “emergency” vulnerability patching process, we can trigger our auto-patching workflow on demand to confidently and quickly beat attackers to the punch.
Concluding Thoughts
While I personally think these proactive vulnerability management ideas could transform the state of vulnerability management for many organizations, I also know that I’m only one person with a limited set of experience and perspectives. Before writing further on this topic, I’m hoping to get feedback from and spur a discussion within the InfoSec community about these ideas.
What aspects of these ideas make sense? What doesn’t make sense? How could they be improved upon?
I’d really love to hear feedback from folks about this!
Thanks for reading :)